Use AI to build the digital version of yourself

Music.AI allows companies and developers to build and scale audio-driven AI products and services. The ecosystem includes a wide range of state-of-the-art AI models that can be combined to deliver customized solutions for a wide range of use cases.
Supercharge chat engagement on your stream with Tangia
AI Voice Generator and AI Song Generator

TopMediai is an AI-powered online platform that offers a comprehensive suite of media tools for video, audio, and photo editing.
Kits AI is an AI voice generation and free AI voice training platform for musicians to use and create AI voices. On Kits.AI you can change your voice using AI artist voices from either our library of licensed or royalty-free voices, create, train, and share your own AI voice from scratch with one-click RVC v2 model training, and upload your existing .pth files to RVC v1 or v2 models for high-quality inference and model sharing.
Text to Speech & AI Voice Generator
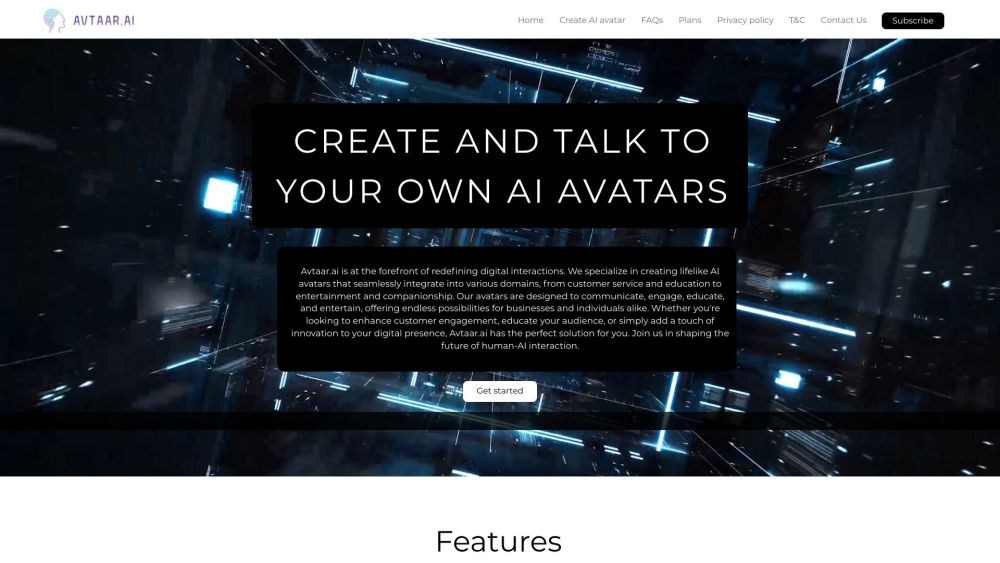
Avtaar.ai crafts hyper-realistic AI avatars using just a photo, voice sample, and context. Ideal for personal AI in EdTech, companionship, and business kiosks.
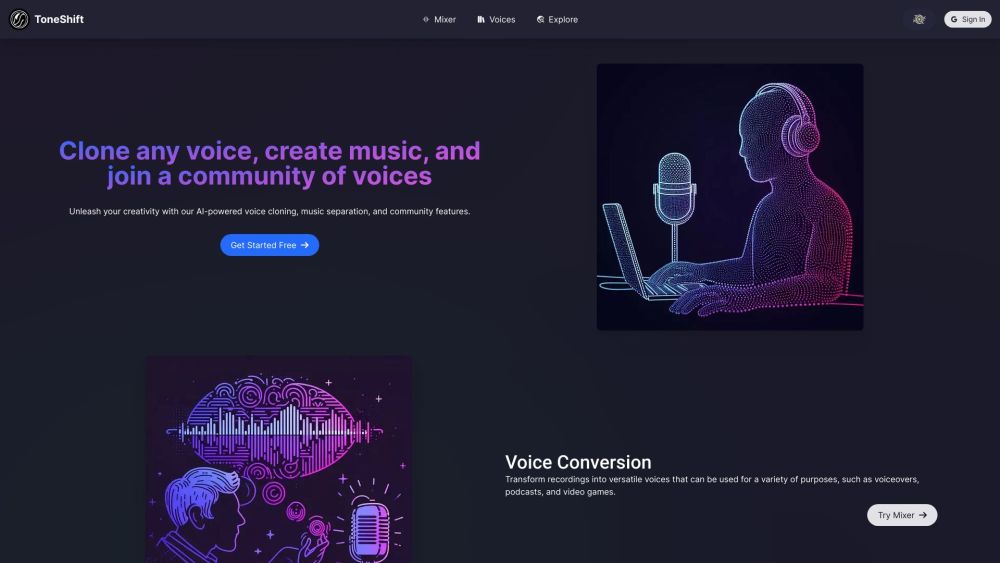
ToneShift is an AI-powered voice cloning and music separation platform.

Vaanee AI is a generative voice AI toolkit that enables users to create realistic human-like voiceovers in seconds.
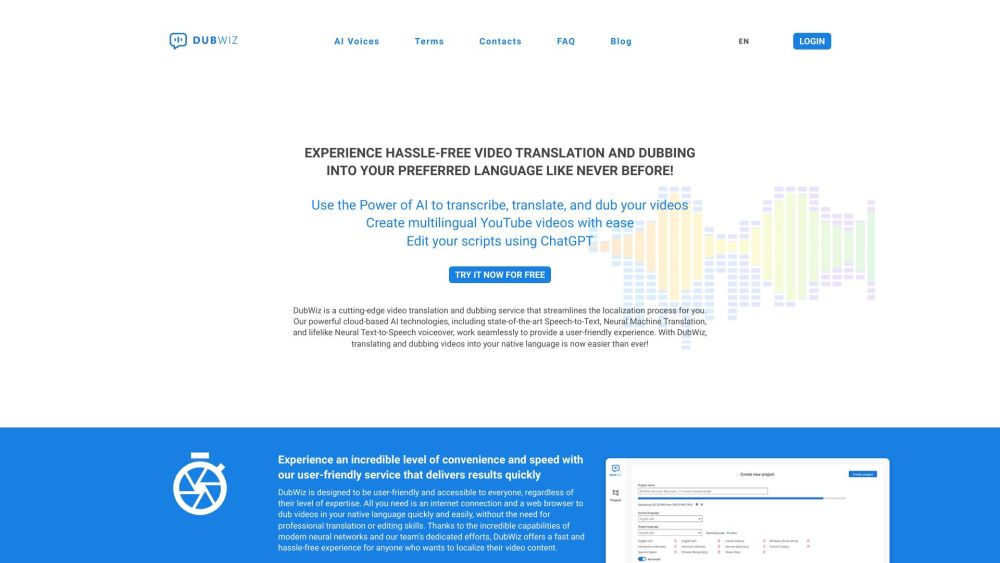
DubWiz is a cutting-edge video translation and dubbing service that streamlines the localization process for you. Our powerful cloud-based AI technologies, including state-of-the-art Speech-to-Text, Neural Machine Translation, and lifelike Neural Text-to-Speech voiceover, work seamlessly to provide a user-friendly experience. With DubWiz, translating and dubbing videos into your native language is now easier than ever!

Instant voice translation for barrier-free meetings
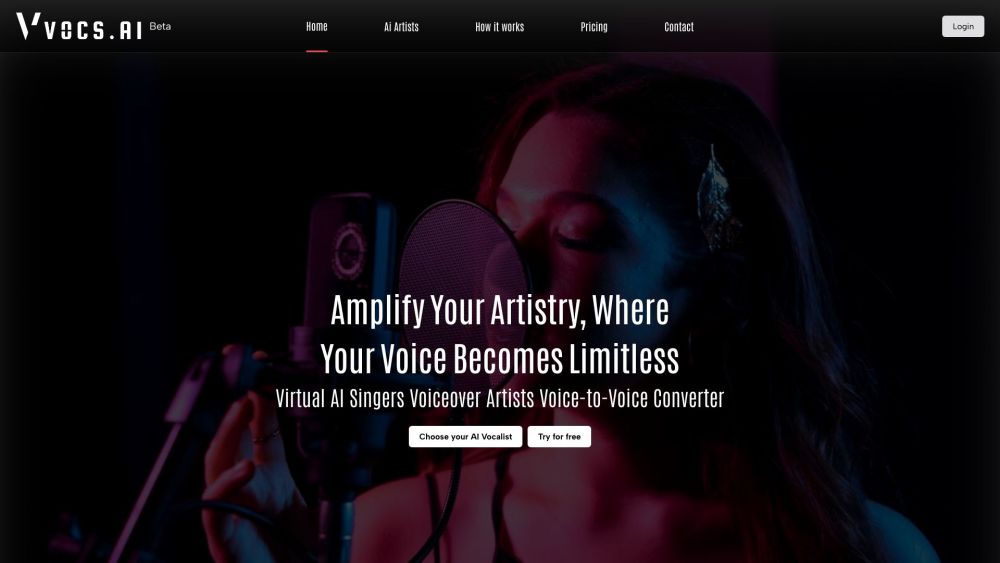
Vocs AI is an AI Voice Generator with over 30 original AI singers, rappers, and voiceover artists for commercial use. It assists music producers, songwriters, ad agencies, game studios, and online creatives around the world.
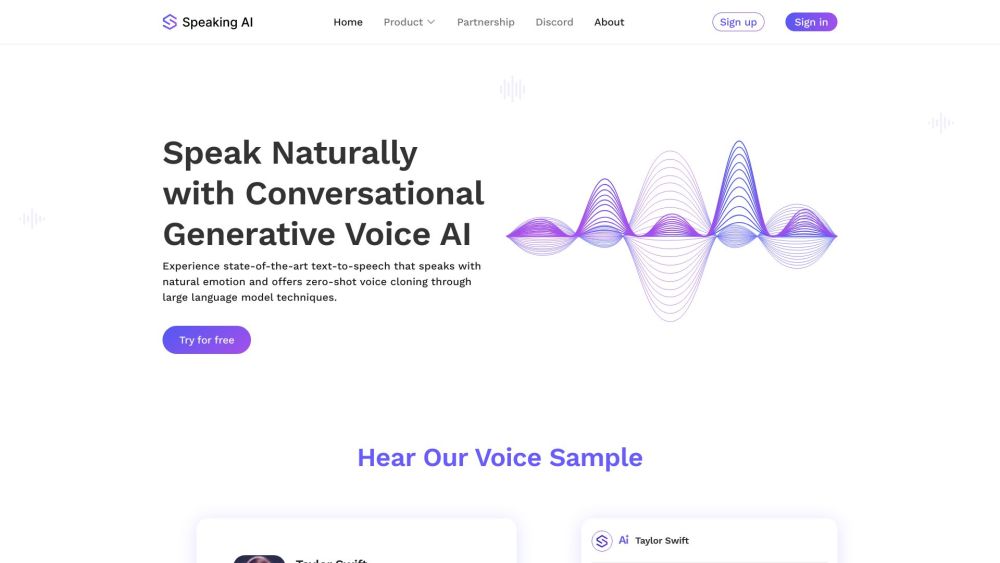
Speaking AI is a beta test for the Foundation Model in generative voice. It allows users to capture their unique tone with just 3 seconds of input and achieve natural-sounding voice quality.
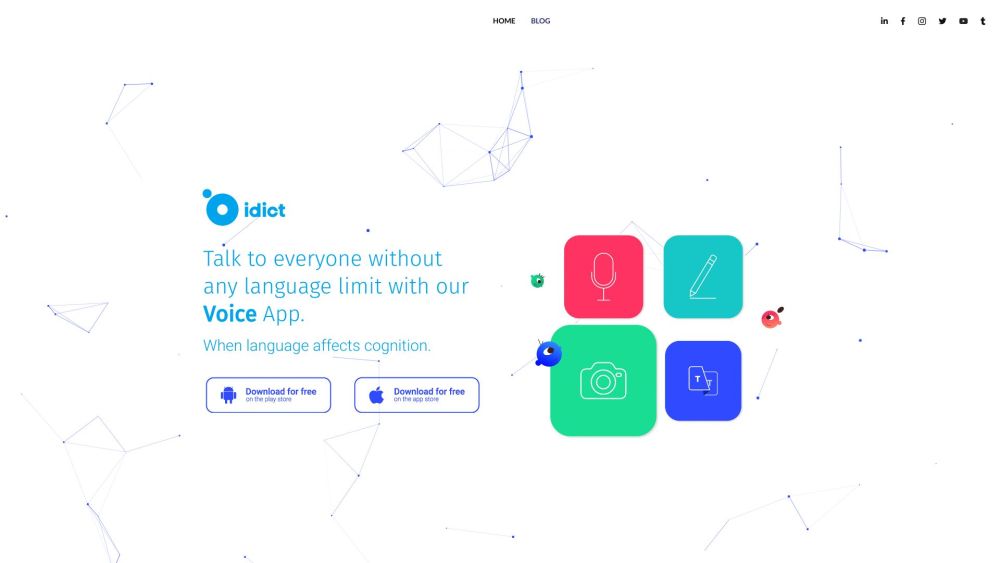
idict is a powerful voice cloning translate app that provides a comprehensive source for all your language needs. It uses Machine Learning (ML) to clone and replicate the sound of a human voice.
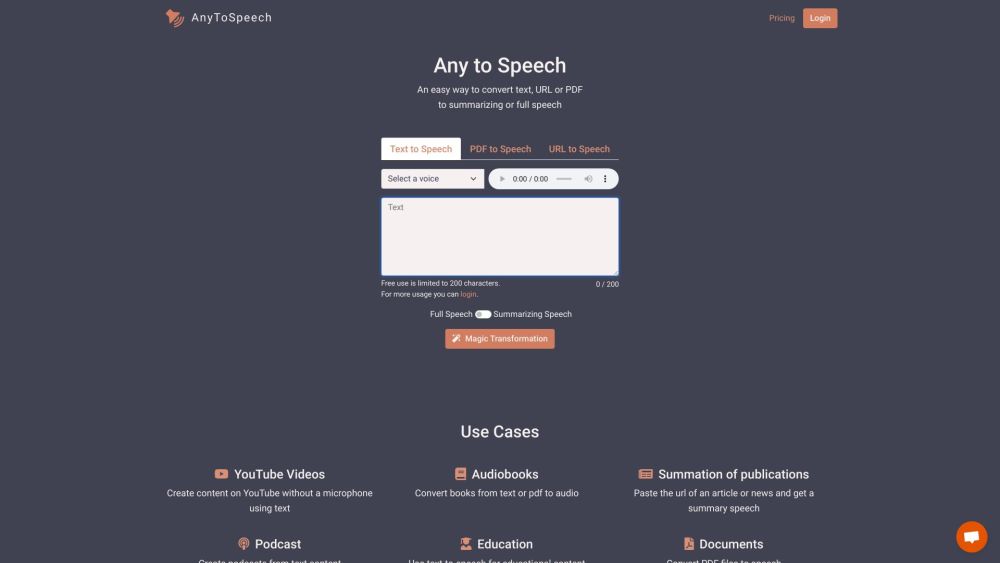
AnyToSpeech is an online text-to-speech converter that allows users to convert text, PDFs, documents, scanned images, and URLs into speech. It offers realistic voices in multiple languages, providing a clean and simple solution for generating audio from text-based content.